
Jelly, the new startup from Biz Stone that’s designed to help people crowdsource answers to any question they may have, has been on the market for around a week now and we’re seeing the first numbers about its usage so far.
RJMetrics, which analyzes engagement data and traffic for a number of startups including Fab, Frank & Oak, Threadless and others, crunched the numbers on Jelly’s first active week using information that’s publicly available through API endpoints that aren’t necessarily publicized very widely yet.
Using his own Jelly account, RJMetrics CEO Robert J. Moore found out the following about usage among Jelly’s network of early adopters:
Total questions asked on the network are around 100,000, which is a big number for one week of active public use.
Of those, around 25,000 or one quarter were answered. It’s not optimal, but it’s also not bad; there’s also a stickiness factor through which each interaction made by a user increases the likelihood they’ll come back and use it again.
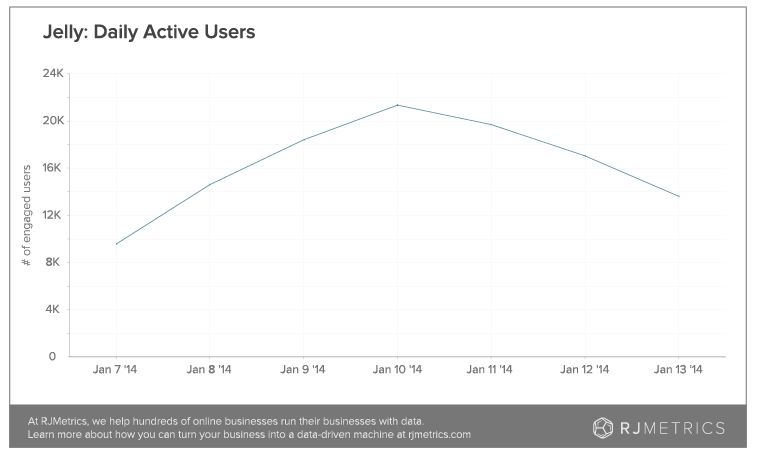 Still, daily active user (DAU) count is trending downward according to Moore’s findings. That’s also to be expected after a high-profile launch, but Moore has found that people answering questions is dropping at a quicker pace than is the number of those doing the asking. He ascribes this to increasing specificity and difficulty in the type of questions being asked as people get used to the service, leading to harder answers. If Jelly can’t provide answers for the questions that members are asking, that doesn’t bode well for long-term viability.
Still, daily active user (DAU) count is trending downward according to Moore’s findings. That’s also to be expected after a high-profile launch, but Moore has found that people answering questions is dropping at a quicker pace than is the number of those doing the asking. He ascribes this to increasing specificity and difficulty in the type of questions being asked as people get used to the service, leading to harder answers. If Jelly can’t provide answers for the questions that members are asking, that doesn’t bode well for long-term viability.
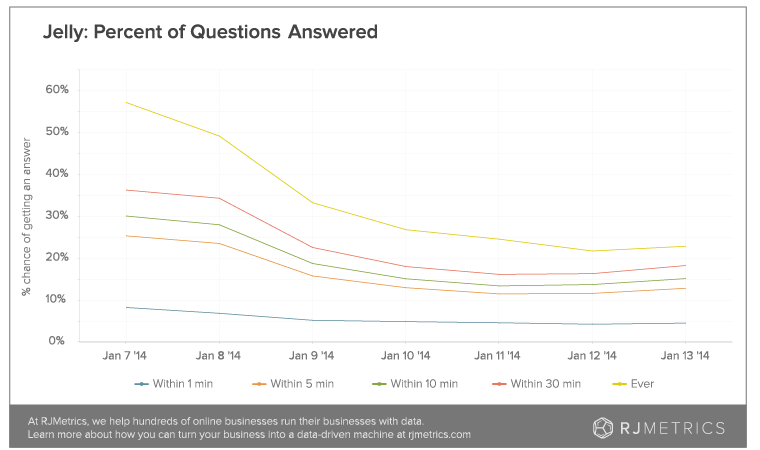 To make sure that people are happy with both the question and answer part of their Jelly experience, it may be useful for the startup to look at what kind of questions are being asked most frequently, and somehow encourage more answers for the more popular types of queries. Once people do answer, they keep coming back to answer more, after all.
To make sure that people are happy with both the question and answer part of their Jelly experience, it may be useful for the startup to look at what kind of questions are being asked most frequently, and somehow encourage more answers for the more popular types of queries. Once people do answer, they keep coming back to answer more, after all.
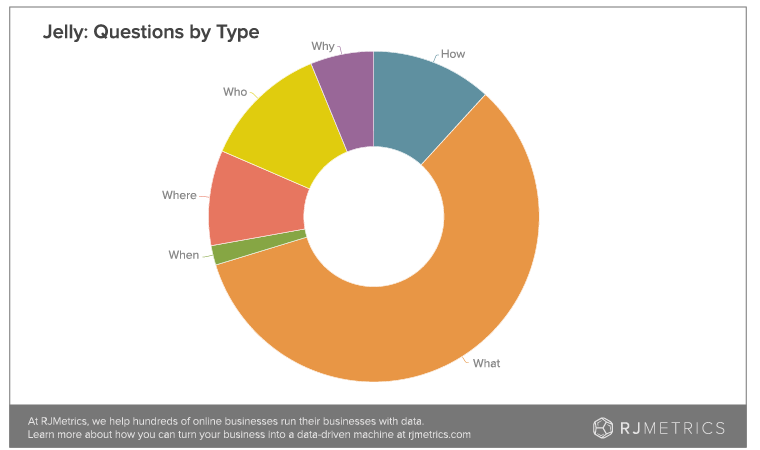
Moore found that “What is this?” accompanied by a photo was the most common type of query by far: Of the top 10 most popular questions on the platform, each contained an image identification aspect. “Who,” “Where,” and “What” were also among the top results according to Moore’s data.
 It’s early days yet for Jelly, and this data may not be providing a complete picture, coming as it does from these unexposed API endpoints. But it’s probably fair to infer that the trends Moore identifies are at least on the right track. Jelly has an interesting model, and one that requires a different kind of engagement from other popular social tools like Twitter and Facebook, but it’s still working out its place in the market, so we’ll be watching to see how community interaction develops in the coming weeks.
It’s early days yet for Jelly, and this data may not be providing a complete picture, coming as it does from these unexposed API endpoints. But it’s probably fair to infer that the trends Moore identifies are at least on the right track. Jelly has an interesting model, and one that requires a different kind of engagement from other popular social tools like Twitter and Facebook, but it’s still working out its place in the market, so we’ll be watching to see how community interaction develops in the coming weeks.

Read more : Jelly Sees 100K Questions In First Week Says RJMetrics, Of Which 25% Received Answers

0 Responses
Stay in touch with the conversation, subscribe to the RSS feed for comments on this post.